# Redis
# 一.redis知识点总结
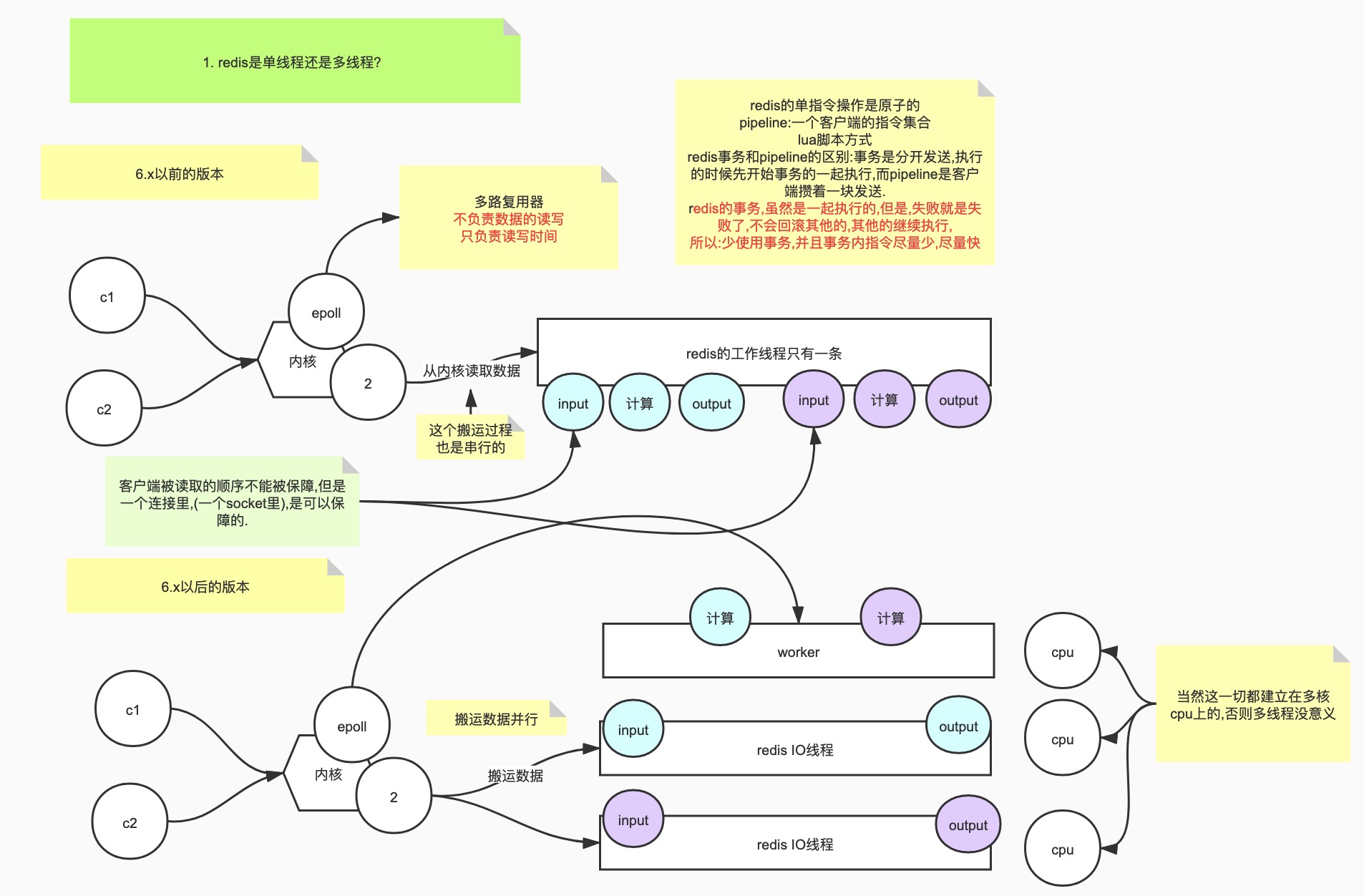
# 1.redis是单线程吗
1,无论什么版本,工作线程就是一个
2,6.x高版本出现了IO多线程
3,使用上来说,没有变化
4, IO多线程,把输入/输出放到更多的线程里去并行,好处如下:1,执行时间缩短,更快;2,更好的压榨系统及硬件的资源(网卡能够高效的使用);
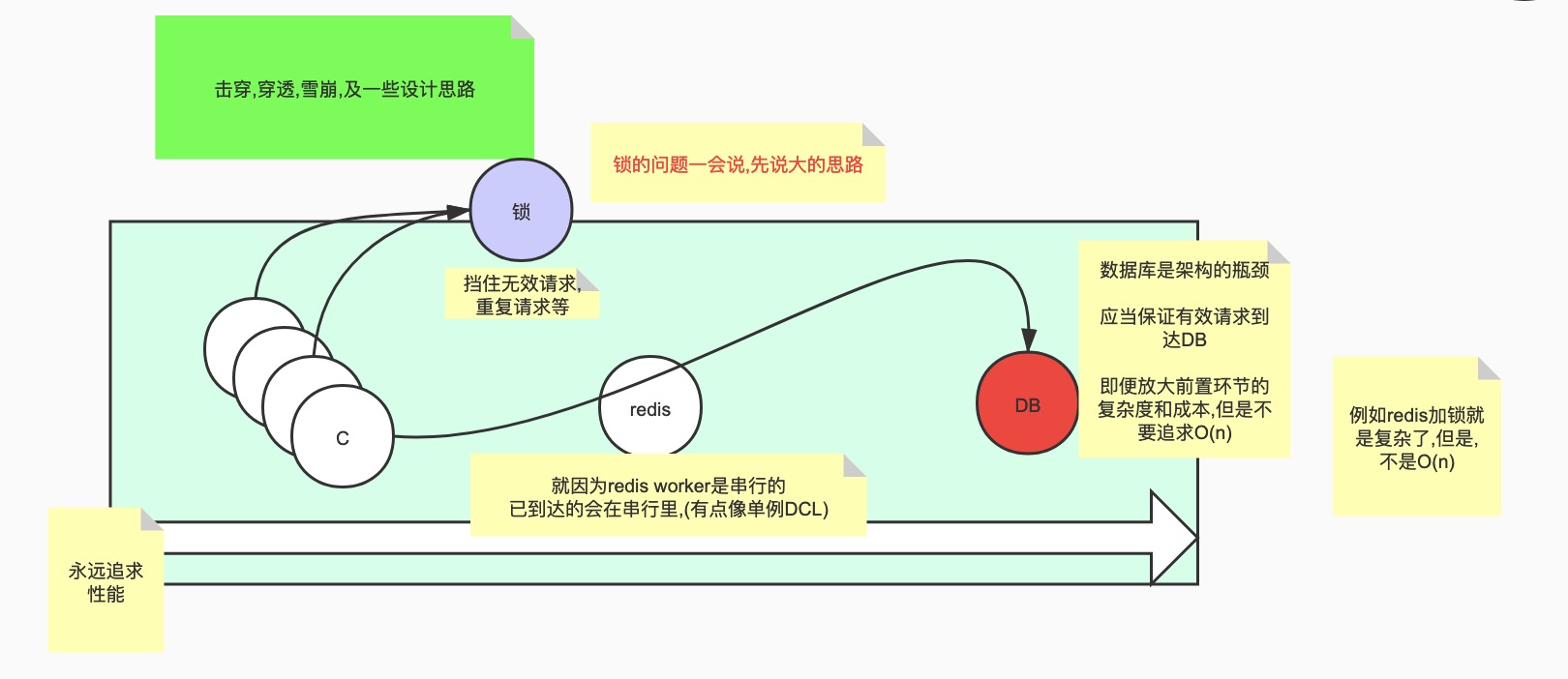
# 2.击穿,穿透,雪崩.
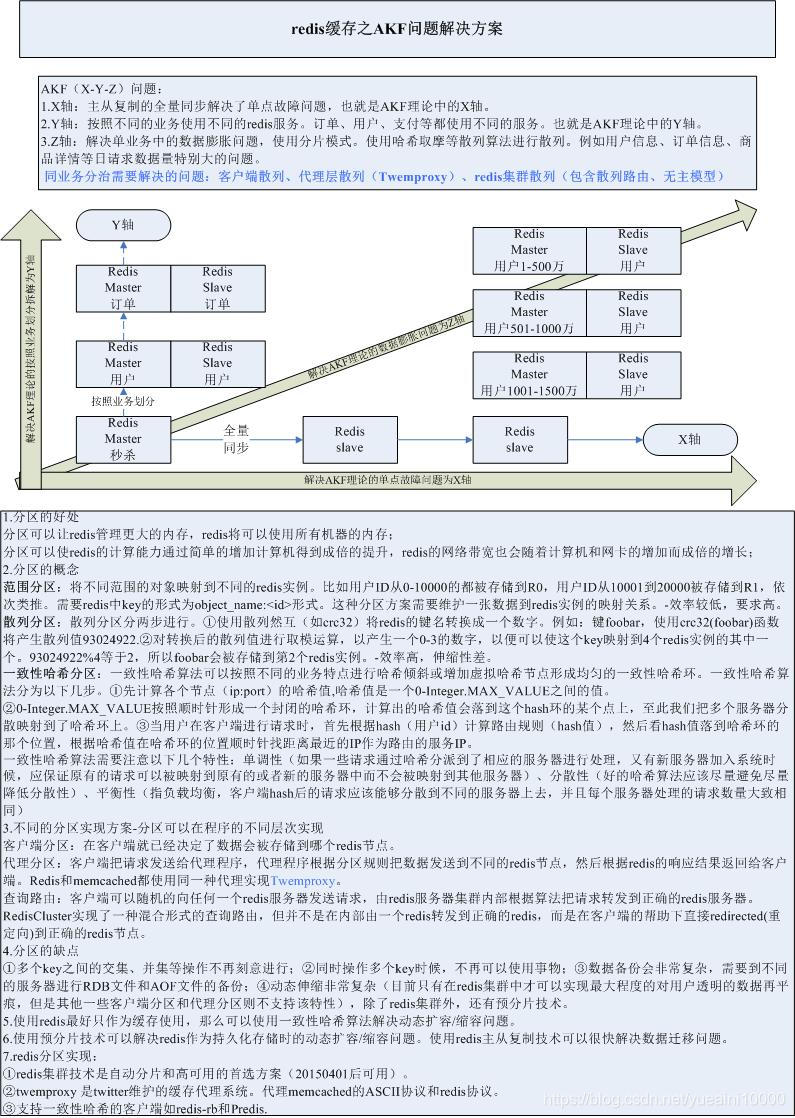
# 3.AKF分治
图解:
# 4.Redis和ZooKeeper怎么选
Redis和ZooKeeper怎么选 (opens new window)
# 二.redis系统学习
# 1.什么是Redis?
redis中文官网 (opens new window)
redis英文官网 (opens new window)
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如 字符串(strings) (opens new window), 散列(hashes) (opens new window), 列表(lists) (opens new window), 集合(sets) (opens new window), 有序集合(sorted sets) (opens new window) 与范围查询, bitmaps (opens new window), hyperloglogs (opens new window) 和 地理空间(geospatial) (opens new window) 索引半径查询。 Redis 内置了 复制(replication) (opens new window),LUA脚本(Lua scripting) (opens new window), LRU驱动事件(LRU eviction) (opens new window),事务(transactions) (opens new window) 和不同级别的 磁盘持久化(persistence) (opens new window), 并通过 Redis哨兵(Sentinel) (opens new window)和自动 分区(Cluster) (opens new window)提供高可用性(high availability)。
# 击穿,穿透,雪崩
# 1.击穿
# 前言:
只有高并发的情况下,才会出现这些问题,否则,小量请求根本不叫事. 真正的客户端,是来源于互联网的那些用户,其实整个网络或者整个项目,用户是造成所有行为的这一端,他们所有的流量压过来之后,如果这一端压力比较大,才会有所谓的高并发,压过来之后,其实一层一层的把这些个流量,全部避掉,最终可能说前面10w个并发,但是经过前面的技术,最终压到数据库就几百,几千,这才是一个架构师看一个项目该做的事情.
# 击穿的发生原理
做缓存的时候,一个k刚好不在了,但是发生了高并发,这就是击穿.
做缓存的时候,必然会有两件事
- key有过期时间,无论如何过期了
- 开启了LRU或者LFU自动把一些相对较冷的数据清除了.留下些热数据.
正是因为这两个点,k刚刚被清掉的时候,一大批流量来了,正好请求这个k,这时候他已经没有了,所以这时候,流量一定会掉头去访问数据库,这时候,等于从redis身上打了个窟窿,穿过去了,就叫击穿.
# 解决方案
# 错误解决方案.
布隆过滤器,
布隆是解决穿透的,不是击穿
延长有效期
作为缓存,内存是有限的,不能让更多数据存更久的时间.而且,无论延长多久,就这么巧,就在消失的这个点,击穿了.
# 正确解决方案.
1.目的是什么,目的是阻止这些高并发流量一下堆到数据库,但是,redis也没有这个k,怎么阻止呢?
redis知识点,redis是单进程,单实例,所有的高并发,都是排队进来的,肯定会存在"第一个人A"发现了redis不存在,去请求库,然后后面的人都发现了,都去请,这时候可以做件事,A回到客户端,后边的人刚进去找,都没找到,都出来了,然后A又成了第一个,他做一个setnx(),只有不存在的时候才可以设置.让所有人都干了这么个事.
A发现了,回来之后,立即创建了个k,就约等于是创建了一把锁,.于是就发生了以下三步.
- 客户端到redis请求,没有那个key,没找到,
- setnx(),设置锁,只有这步设置成功的哥们,才可去访问数据库,
- 只有获得锁的人才能访问数据库.
代码逻辑就是这样,锁成功的人去请求,失败的人等待一下再来请求.1.getkey,2.失败,都去setnx(),3-1成功的人去访问数据库,3-2失败的人睡眠一会,醒了之后,从1开始.
2.衍生问题:
2-1. 睡多久合适
其实你要评测下,从你的服务访问数据库平均损耗多少毫秒,这个不能让他们睡很久,几秒钟的话,前面的整个所有链就超时了,
2-2.最主要的问题.发生死锁.
"第一个人A",锁上了,忙事去了,结果他挂了,锁在那放着,没人把请求补上去,其他的高并发请求就一直循环在那睡.所以,这个锁,不能是死锁,得是活锁,
没错,锁也是可以设置超时时间的,我们给锁设置一个过期时间,比如1s,(不短了),这时候,即使他挂了,1s后,别的请求看到锁没了,k也没有,还有个人可以重新上锁去请求,由下个人替补去取这个数据.
但是但是但是!!!!,分布式中,最头疼的,就是大家都是分开的,过期时间怎么设置,长了,刚开始就挂了,别人要浪费很多时间,短了,他没干完事呢,锁就过期了,他没更新数据呢.别人又来了,还是一样拥塞着.其实看上去好像没多大问题.就是第一个出来了,还有几个在那拥塞着呢,就在那等.所以可能造成几个客户延迟,丢失等. 怎么解决呢?多线程!一个线程去取DB,另一个线程去监控他取回来没有,然后更新,延长锁的时间.这时候,多加一个更新线程,即使第一个哥们挂了,锁可能会超时,那么这个就靠超时来解决,第一个没挂, 他时间延长了,他不会造成别人排队干这个事.是一个解决方案.但是代码逻辑复杂度提高.
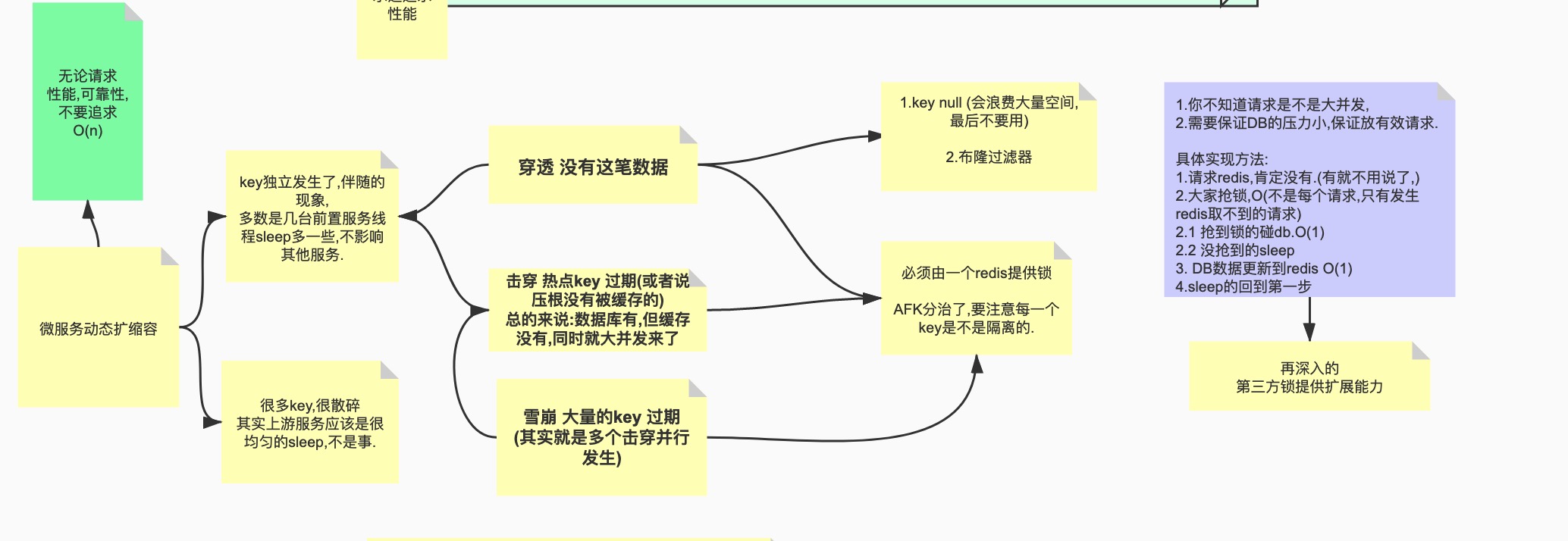
# 2. 穿透
# 前言:
只有作为缓存才有这个问题.
# 穿透发生原理
击穿,说的是一个k刚好不在了,然后要去数据库取,穿透呢,指的是你查的根本就是一个连数据库中都不存在的数据,甭说缓存没有,数据库都没有.但是呢,业务里,缓存没有,全都压到数据库,再去做查询的话,也是消耗性能.
# 解决方案
布隆过滤器,当然,那也是有几种使用方法的.
客户端里植入布隆过滤器的相应算法,让所有客户端就包含了,如果客户端就包含了布隆,以及缓存了一些数据的话,这意味着,连redis的压力都没了.
优点:
如果客户端包含过滤逻辑,那么一定会过滤部分请求,减少压力,到不了redis.
缺点:
对客户端内存要求比较大
客户端只有算法,布隆过滤器的bitmap还是在redis中,
redis中集成布隆模块,变成一个个指令,
优点:
客户端变得简单
缺点:
所有东西都压到了redis
布隆过滤器有一个缺点:布隆过滤器只能增加,不能删除.!!!,如果你业务中,大量数据增删改时候,有些数据被删掉,这时候你只能往里增,那么代表着,布隆一查有,结果没有了,到数据库了,你要么给他置空,要么换一个,比如布谷鸟或者布隆过滤器+,能支持删除的.置空的话,反正redis查的时候,就返回了,也不会触发布隆那个环节,总之,既能用到布隆过滤器,组织流量到达他, 也得支持数据的变化.
# 3.雪崩
# 前言:
也是只有作为缓存的时候,才考虑这个问题.
# 雪崩发生原理
有点像击穿,击穿是一个k不见了,导致压到数据库,但是这个问题,好像并不是那么容易发生,反而雪崩,处理不好反而更容易发生.
什么时候产生雪崩?是大量的k同时失效,自己同时过期,比如半夜12点,新的一天,老的全部过期,这样会造成大量的k同时失效,这时候,间接导致大量请求到达了数据库,这种场景更真实一点,均匀每个k被几十几百请求,全压过去了.怎么解决?
# 解决方案
# 错误解决方案:
均匀分布过期时间.
为什么?刚刚说过了,雪崩如何产生的,某个时间点,大量k同时过期,注意看,某个时间点,大量k,某个时间点!!!就是说,在那个点,老的k必须换掉,新的k必须压上来,你均匀分布过期了,老的k没换掉,就会产生脏读,这是很危险的,
# 正确解决方案:
你要分开场景说,如果跟时点性无所谓,那么就是时间没调好,可以用过期时间这个事了,但是如果某个点必须过期,就不要用它了,那么这种某点必须过期,怎么处理呢.
强依赖击穿方案.
如果你整个框架都知道,这些数据会在某个点过期,你可以在业务中加个前置.加个判断,叫做零点延迟.
什么意思呢.?你的业务,到了那个点了,将请求都随机睡一下,不要把流量都放过来,有了这个延迟,就可以把流量到达的时间不一样.这时候,阻塞不会大,流量也变小,后面人来的时候,前面的人已经更新完了,
# 要有全局感
你会选择在不同的点上尽量的限流,把流量控制住,越往后到达越少,越精准.
← 设计模式 redis系统性学习 →